Continuous Profiling with Middleware
When software applications are first built, they may initially meet our requirements. However, it’s not enough for our applications to simply meet the bare minimum. We also want them to be as efficient as possible, but figuring out how or where to improve them can be challenging.
What is Profiling?
Profiling, in the context of software development, refers to the process of analyzing and measuring the performance characteristics of a program or system.
It involves using specialized tools known as application profiling tools to gather metrics like CPU usage, memory allocation, and execution time.
What is Continuous Profiling?
Continuous profiling takes things a step further by enabling real-time monitoring and detection of performance regressions. It allows developers to proactively address any emerging issues before they impact users.
Continuous Profiling can be set up easily using any of our APMs.
Continuous Profiling Support Matrix
The following table shows what Continuous Profiling features are available per each APM:
| Profiling Query Type | Node.js | Go | Java | Ruby | .NET | PHP | Python | Next.js | Vercel | Cloudflare | Scala | |
| Object Allocation | memory:alloc_objects:count:: | ✖️ | ✅ | ✖️ | ✖️ | ✖️ | ✖️ | ✖️ | ✖️ | ✖️ | ✖️ | ✖️ |
| Memory Allocation | memory:alloc_space:bytes:: | ✖️ | ✅ | ✖️ | ✖️ | ✖️ | ✖️ | ✖️ | ✖️ | ✖️ | ✖️ | ✖️ |
| Objects in Use | memory:inuse_objects:count | ✅ | ✅ | ✖️ | ✖️ | ✖️ | ✖️ | ✖️ | ✅ | ✅ | ✖️ | ✖️ |
| Memory in Use | memory:inuse_space:bytes | ✅ | ✅ | ✖️ | ✖️ | ✖️ | ✖️ | ✖️ | ✅ | ✅ | ✖️ | ✖️ |
| CPU Usage | process_cpu:cpu:nanoseconds:cpu:nanoseconds | ✖️ | ✅ | ✅ | ✅ | ✖️ | ✖️ | ✅ | ✅ | ✅ | ✖️ | ✅ |
| Wall-clock time | wall:wall:nanoseconds:cpu:nanoseconds | ✖️ | ✖️ | ✖️ | ✖️ | ✅ | ✖️ | ✖️ | ✖️ | ✖️ | ✖️ | ✖️ |
| Blocking Contentions | block:contentions:count:: | ✖️ | ✖️ | ✅ | ✖️ | ✖️ | ✖️ | ✖️ | ✖️ | ✖️ | ✖️ | ✅ |
| Blocking Delays | block:delay:nanoseconds:: | ✖️ | ✖️ | ✅ | ✖️ | ✖️ | ✖️ | ✖️ | ✖️ | ✖️ | ✖️ | ✅ |
| Bytes Allocated(TLAB) | memory:alloc_in_new_tlab_bytes:bytes:: | ✖️ | ✖️ | ✅ | ✖️ | ✖️ | ✖️ | ✖️ | ✖️ | ✖️ | ✖️ | ✅ |
| Objects Allocated(TLAB) | memory:alloc_in_new_tlab_objects:count:: | ✖️ | ✖️ | ✅ | ✖️ | ✖️ | ✖️ | ✖️ | ✖️ | ✖️ | ✖️ | ✅ |
Profiling A Flask Web Application
Prerequisites
MW Agent Installed
The MW Host Agent must already be installed
VPS or Cloud Computer
Access to a VPS or a cloud computer service instance like EC2, Azure VM, or Digital Ocean Droplet
Create Your Flask App
Finding a Bottleneck
After creating the application and deploying it to the platform of your choice, follow the steps from Python APM, login to middleware.io, and head to APM > Continuous Profiling.
To identify individual functions/methods that consume a significant amount of CPU time, click on the Table and Flamegraph section.
Within the table, sort the functions/methods by the amount of time they consume in descending order by clicking on the “Self” header.
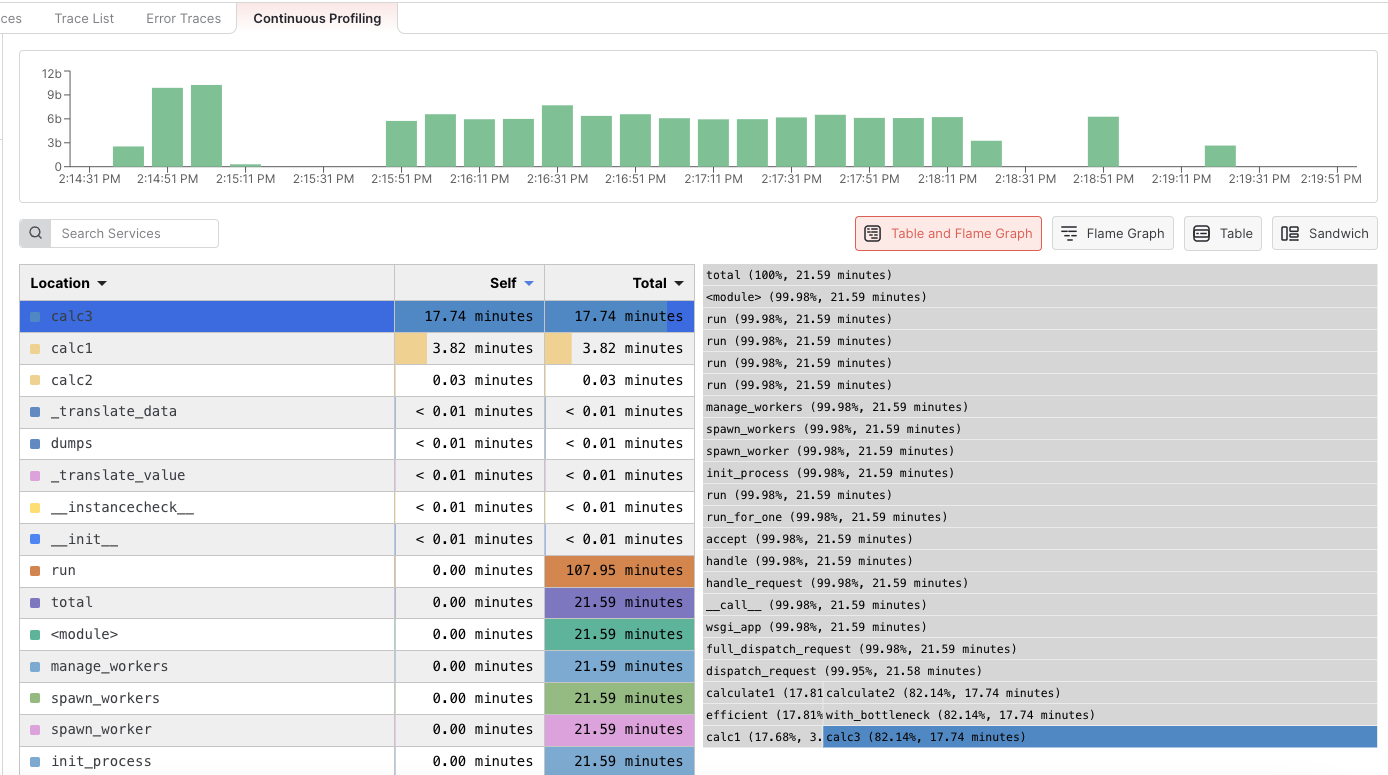
In this example, it’s clear that the calc3 function is causing a notable bottleneck in our application.
By clicking on the function name calc3 in the table, the function will also be highlighted in the flame graph. This will show the call stack with caller functions at the top and callee functions going toward the bottom.
Was this page helpful?